
해시 함수(Hash Function)
해시 함수(Hash Function)란 주어진 원문에서 고정된 길이의 의사난수를 생성하는 연산기법이며, 이에 생성된 값을 '해시값'이라고 한다. 다시 말해 해시 함수는 임의의 길이의 데이터를 고정된 길이의 데이터로 변환하는 함수이다. 해시 함수에 의해 얻어지는 값을 해시 코드, 해시 값, 메시지 다이제스트 또는 해시(Hash)라고 한다.
암호화 해시 함수(cryptographic hash function)는 해시 함수의 일종으로, 해시 코드로 부터 원래의 입력값을 추정하기 어려운 성질을 가지는 경우를 의미한다. 암호화라는 의미가 암호문으로 부터 암호화하기 전의 평문을 추정하기 어렵게 만든 것이기 때문이다. 이 암호화 해시 함수에는 MD5, SHA, SHA‐1, SHA‐256 등의 알고리즘이 있다.
역상(pre-image), 제2역상(2nd pre-image), 충돌쌍(collision)
암호화 해시 함수는 역상(pre-image), 제2역상(2nd pre-image), 충돌쌍(collision)에 대하여 안전성을 가져야 하며 인증에 이용된다. 아래는 위 3가지 경우에 대해 해시 함수가 가져야하는 기본 성질이다.
| 성질 | 설명 |
| 역상 저항성(pre-image resistance) | 주어진 임의의 출력값 y에 대해 y=h(x)를 만족하는 입력값 x를 찾는 것이 계산적으로 불가능 |
| 제2역상 저항성(2nd pre-image resistance) | 주어진 입력값 x에 대해 h(x)=h(x'), x≠x'을 만족하는 다른 입력값 x'을 찾는 것이 계산적으로 불가능 |
| 충돌 저항성(collision resistance) | h(x)=h(x')을 만족하는 임의의 두 입력값 x, x'을 찾는 것이 계산적으로 불가능 |
위의 이유로 인해 해시 함수는 서로 다른 입력값으로 부터 동일한 출력값이 나올 가능성이 희박하므로 입력 값에 대한 무결성 보장되어야 한다. 당연히 입력 값이 바뀌면 출력값도 달라지게 되며, 원본이 변경되지 않았다는 것을 입증할 때 출력값이 동일하다면 데이터에 대한 무결성 보장되어야 한다. 다만 해시함수는 MD Strength Padding할 때 길이정보가 입력되므로 최대 길이에 대한 제한이 있다. 예를 들어 패딩시 하위 8비트에 길이정보가 입력 되는 경우에는 해시가능한 최대 길이는 0xFF가 되어 255바이트가 된다. 실제 길이정보는 패딩방식에 따라 다를 수 있다.
또 다른 해시 함수의 특징은 통상적으로 다른 암호체계와 다르게 키가 필요하지 않다는 것이다. 즉, 평문을 해시 함수로 변환하면 마치 하나의 변수에 대응하는 함수 값이 하나인 것처럼 항상 같은 해시 코드를 얻는다. 최초의 암호 기계인 에니그마(Enigma)의 암호체계에서 20글자로 이루어진 평문을 암호화하면 그 암호문은 역시 20글자로 이루어진다. 교란 목적 혹은 인증 목적에 따라 사용자 간 암호화 약속에 따라 다른 부가적인 문자열이 추가될 수 있다. 따라서 암호문은 더 길어지면 길어지지 짧아지지는 않는다.
그러나 해시 함수의 경우는 입력값의 크기에 상관없이 똑같은 크기의 해쉬코드를 만들어낸다. 일반적으로 해시 코드는 입력값보다 크기가 작다. 다시 말해 해시 코드의 내용은 달라지지만 길이는 항상 같다. 압축함수는 원래의 크기로 복원이 가능하지만 해쉬함수의 경우는 복원할 필요가 없고 복원이 가능해서도 안 된다.

이 해시 함수는 디지털 문서에 대한 조작이 있는지 없는지에 대한 판단을 할 수 있는 수단을 제공한다. 예를들어 중요한 문서를 이메일로 수신하였는데 수신자로 하여금 이 문서가 중간에 수정되거나 삭제되는 등의 조작이 있었는지를 확인할 수 있게 해주는 과정은 다음과 같다.
- 사용자는 상호간 같은 해쉬함수를 공유한다.
- 송신자는 전송하고자 하는 문서의 해쉬코드를 그 해쉬함수를 이용하여 생성한다.
- 문서와 해쉬코드를 전송한다.
- 수신자는 수신한 문서와 해쉬코드를 분리하고 자신이 보유한 해쉬함수를 이용하여 문서의 해쉬코드를 생성한다.
- 수신한 해쉬코드와 수신자 자신이 생성한 해쉬코드를 비교한다.
만약 두 개의 해쉬코드가 일치하지 않는다면 "어떤 입력값에 의해 생성된 해쉬코드와 같은 해쉬코드를 생성하는 다른 입력값을 찾는 것이 어렵다"는 성질에 의해 문서가 조작되었다는 결론을 내릴 수 있다. 여기에는 작은 정보, 예를들어 하나의 비트값만 달라져도 해쉬값은 아주 크게 달라진다는 눈사태효과(Avalanche effect)가 작용한다. 그래서 문서를 아주 정교하게 변조한다해도 그 해쉬값은 크게 달라지므로 해쉬값을 이용해서 쉽게 변조를 탐지할 수 있는 것이다.
아래는 sha256을 이용한 해시 값 비교이다.
sha256(“Alien Coder”) => 7de461828f6ac9e8f5e48b23ceebd69b1556875b3571258e0a9733d0b594e126
sha256(“Alien coder”) => d3036c054509faf631749643f6e7a85150b80640cf9ce16b47aa223f3834fb5d
그렇다면 해시 함수는 완벽한 방법이라 볼 수 있는가? 그렇지는 않다. 해시함수를 공격하는 방법은 세 가지가 있다.
- 역상공격(preimage attack): 주어진 해시 결과값을 가지고 입력값을 찾는 공격법
- 제2역상공격(second preimage attack): 어떠한 입력에 대한 해시 결과값을 가지고 같은 해시값을 찾아 그에 해당하는 입력을 구하는 공격법
- 충돌공격(collision attack): 생일 역설(birthday paradox)을 근거로 앞의 두 가지 공격 방법보다 공격 성공률이 높은 방법. Birthday Attack으로도 불리며 동일한 해시 결과값을 갖는 충돌쌍(똑같은 해시값을 반환하는 서로 다른 데이터의 쌍)을 찾는 공격법
생일 역설(birthday paradox)
가장 성공률이 높은 충돌 공격에 사용되는 생일 역설(birthday paradox)이론은 사람이 임의로 모였을 때 그 중에 생일이 같은 두 명이 존재할 확률을 구하는 문제이다. 생일의 가능한 경우의 수는(2월 29일을 포함하여) 366개이므로 367명 이상의 사람이 모인다면 비둘기집 원리에 따라 생일이 같은 두 명이 반드시 존재하며 23명 이상이 모인다면 그 중 두 명이 생일이 같은 확률은 1/2를 넘는다.
이는 생각보다 꽤 확률이 높다. 얼핏 생각하기에는 생일이 366가지이므로 임의의 두 사람의 생일이 같을 확률은 1/366이고, 따라서 367명쯤은 모여야 생일이 같은 경우가 있을 것이라고 생각하기 쉽다. 그러나 실제로는 23명만 모여도 생일이 같은 두 사람이 있을 확률이 50%를 넘고, 57명이 모이면 99%를 넘어간다. 반대로 생각하면, 이 문제는 무작위로 만난 367명의 생일이 서로 겹치지 않고 고르게 분포할 확률이 매우 극히 낮다는 점을 나타낸다.
아래는 생일 역설을 설명하는 수식이다.
$$ \bar{p}(n) = 1 * (1-{1\over365}) * (1-{2\over365}) * ... * (1-{n-1\over365}) = {365!\over365^n(365-n)!} $$
| 1 | 0.0% |
| 5 | 2.7% |
| 10 | 11.7% |
| 20 | 41.1% |
| 23 | 50.7% |
| 30 | 70.6% |
| 40 | 89.1% |
| 50 | 97.0% |
| 60 | 99.4% |
| 70 | 99.9% |
| 100 | 99.99997% |
| 200 | 99.9999999999999999999999999998% |
| 300 | (100 − (6×10−80))% |
| 350 | (100 − (3×10−129))% |
| 365 | (100 − (1.45×10−155))% |
| 366 | 100% |
| 367 | 100% |
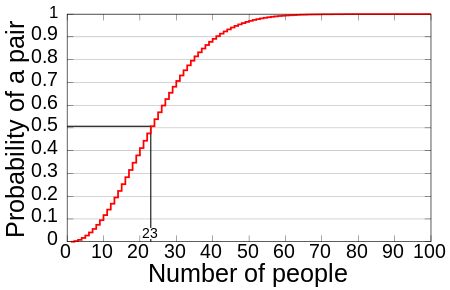
이를 통해 모수가 크지 않더라도 해시함수의 주어진 출력으로부터 입력을 찾아내는 것이 가능함을 알 수 있다. 하지만 이를 찾아내기는 쉽지 않다. 아래는 충돌쌍을 찾아내기 위해 투입된 자원이다.
- SHA-1 계산 총량: 9 quintillion(10^18), 한국 단위로 900경(京) (9,223,372,036,854,775,808)
- CPU 계산속도 기준 6,500년 소요
- GPU로 치면 110년 소요 (*110개의 GPU를 병렬 처리하면 1년)
해시함수의 충돌쌍 발견 사례를 요약하면 아래와 같다.
- 2004년 8월: MD5를 포함한 다양한 해시함수에서 충돌쌍 발견
- 2004년 8월: SHA-0의 충돌쌍 발견, 복잡도 251, 8만 CPU 시간 소요(256개의 Itanium2 프로세서 장착한 수퍼 컴퓨터를 full-time 사용하여 13시간 연산하는 것과 동일한 시간)
- 2005년 2월: SHA-1의 충돌쌍 발견(SHA-1 160비트의 경우)
- 2008년: TLS(Transport Layer Security)에서 사용되는 인증서 내 사용된 MD5 충돌쌍 발견
- 2017년 2월: CWI+구글 SHA-1의 PDF형식의 충돌쌍 발표
충돌쌍이 발견된 해시 함수(MD2/MD4/MD5, SHA-0/SHA-1 등) 선택을 피하고 SHA-256이나 SHA-3와 같은 최신 해시함수 선택을 하여 안전하게 데이터를 보호할 수 있다.
참고 자료
https://ko.wikipedia.org/wiki/%ED%95%B4%EC%8B%9C_%ED%95%A8%EC%88%98
https://ko.wikipedia.org/wiki/%EC%83%9D%EC%9D%BC_%EB%AC%B8%EC%A0%9C
https://medium.com/nybles/hashing-algorithms-d10171ca2e89
https://codedragon.tistory.com/6260
http://psychoblocks.blogspot.com/2018/02/hash-function.html
