
투시변환(Perspective Transform)
영상의 기하학적 변환 중 어파인 변환(Affine Transform)보다 자유도가 높은 투시변환(Perspective Transform)이 있다. 따라서 투시변환은 직사각형 뿐만 아니라 사다리꼴 혹은 다른 형태의 임의의 사각형으로 표현이 가능하다.
어파인 변환은 우선 원본 이미지에 3개의 점을 정하고, 이 3개 점을 기준으로 얼마나 뒤틀리게 할것인지 정한다.
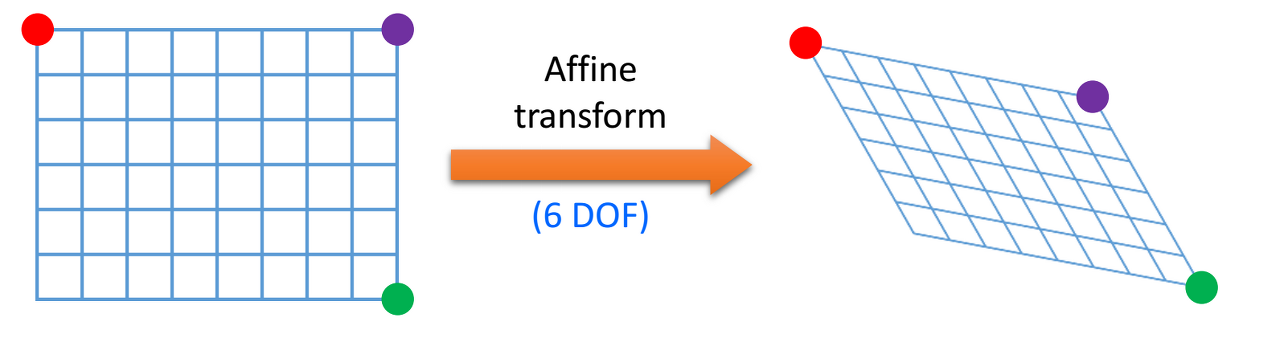
반면 투시 변환은 이미지의 끝 점 4개의 이전위치와 변환 후의 위치를 알면 이동 관계를 알 수 있는데 이는 평행 사변형이 아닌 좀 더 자유로운 사각형이기 때문이다.
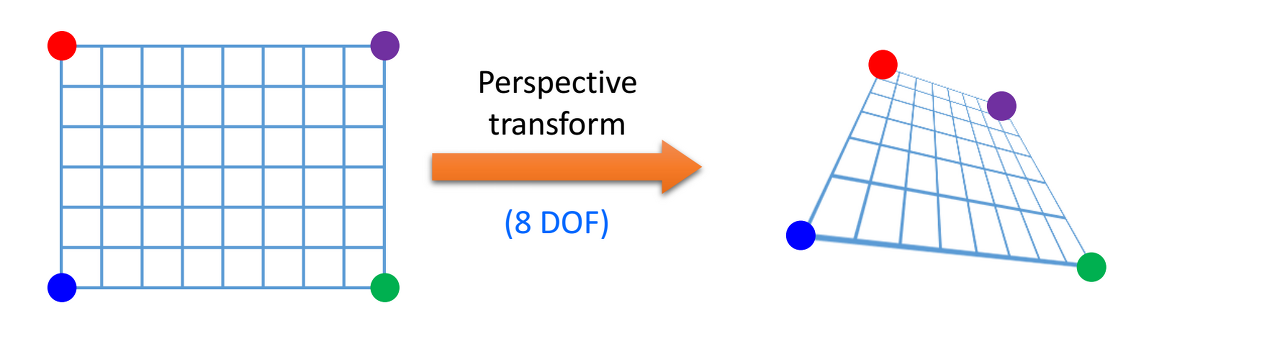
투시 변환은 보통 3×3 크기의 실수 행렬로 표현한다. 투시 변환은 여덟 개의 파라미터로 표현할 수 있지만, 좌표 계산의 편의상 아홉 개의 원소를 갖는 3×3 행렬을 사용한다. 투시 변환을 표현하는 행렬을 \(M_P\)라 하면, 입력 영상의 픽셀 좌표 (x, y)가 행렬 \(M_P\)에 의해 이동하는 결과 영상 픽셀 좌표 (x′, y′)는 아래와 같이 계산된다.
$$ \begin{bmatrix}wx'\\wy'\\w\end{bmatrix}=M_P\begin{bmatrix}x\\y\\1\end{bmatrix}=\begin{bmatrix} p_{11} & p_{12} & p_{13} \\ p_{21} & p_{22} & p_{23} \\ p_{31} & p_{32} & p_{33} \end{bmatrix} \begin{bmatrix}x\\y\\1\end{bmatrix}$$
앞의 행렬 수식에서 입력 좌표와 출력 좌표를 (x, y, 1), (wx′, wy′, w) 형태로 표현한 것을 동차 좌표(homogeneous coordinates)라 하며, 좌표 계산의 편의를 위해 사용하는 방식이다. 여기서 w는 결과 영상의 좌표를 표현할 때 사용되는 비례 상수이며, w=p31x+p32y+p33 형태로 계산된다. 따라서 x′과 y′은 아래와 같다.
$$ x'=\frac{p_{11}x+P_{12}y+p_{13}}{p_{31}x+P_{32}y+p_{33}} $$
$$ y'=\frac{p_{21}x+P_{22}y+p_{23}}{p_{31}x+P_{32}y+p_{33}} $$
OpenCV는 점 4개의 이동 전, 이동 후 좌표를 입력하면 투시 변환 행렬을 반환하는 함수를 제공한다.
cv2.getPerspectiveTransform(src, dst, solveMethod=None)
- src: 4개의 원본 좌표점.
예) numpy.ndarray. shape=(4, 2) => np.array([[x1 , y1 ], [x2 , y2 ], [x3 , y3 ], [x4 , y4 ]], np.float32) - dst: 4개의 결과 좌표점.
예) numpy.ndarray. shape=(4, 2) - retval: 3x3 투시 변환 행렬
투시 변환 함수에 투시 변환 행렬을 입력하면 투시 변환 행렬이 적용된 영항을 출력할 수 있다.
cv2.warpPerspective(src, M, dsize, dst=None, flags=None, borderMode=None, borderValue=None)
- src: input image
- M: 3x3 투시 변환 행렬. 실수형.
- dsize: 결과 영상 크기. (w, h) 튜플. (0, 0)이면 src와 같은 크기로 설정
- dst: 출력 영상
- flags: 보간법. default=cv2.INTER_LINEAR
- borderMode: 가장자리 픽셀 확장 방식. default=cv2.BORDER_CONSTANT
- borderValue: cv2.BORDER_CONSTANT일 때 사용할 상수 값. default=0
아래는 위 함수들을 이용하여 투시 변환을 수행하는 python 소스 코드이다.
import cv2
import numpy as np
img = cv2.imread('brokenEgg.jpeg')
img = cv2.resize(img, dsize=(640, 480), interpolation=cv2.INTER_AREA)
rows, cols = img.shape[:2]
# 원근 변환 전 후 4개 좌표
pts1 = np.float32([[0, 0], [0, rows], [cols, 0], [cols, rows]])
pts2 = np.float32([[100, 50], [10, rows-50], [cols-100, 50], [cols-10, rows-50]])
# 변환 전 좌표를 원본 이미지에 표시
cv2.circle(img, (0, 0), 10, (255, 0, 0), -1)
cv2.circle(img, (0, rows), 10, (0, 255, 0), -1)
cv2.circle(img, (cols, 0), 10, (0, 0, 255), -1)
cv2.circle(img, (cols, rows), 10, (0, 255, 255), -1)
# 원근 변환 행렬 계산
mtrx = cv2.getPerspectiveTransform(pts1, pts2)
# 원근 변환 적용
output = cv2.warpPerspective(img, mtrx, (cols, rows))
result = np.hstack((img, output))
cv2.imshow('result', result)
cv2.imwrite('result.png', result)
cv2.waitKey()
관련 포스트
참고 자료
https://deep-learning-study.tistory.com/200
https://thebook.io/006939/ch08/02-01/
https://velog.io/@nayeon_p00/OpenCV-%ED%88%AC%EC%8B%9C-%EB%B3%80%ED%99%98
소스 코드
https://github.com/sehoon787/Personal_myBlog/blob/main/Data%20Science/CV/PerspectiveTransform.py
